(RSS 20) Event-driven visual-tactile sensing and learning for robots
(RSS 20) Event-driven visual-tactile sensing and learning for robots
望秋弥茂0 Abstract
0.1 Contribution
- 贡献一种事件驱动 Event-Driven 的 视觉–触觉 Visual-Tactile 传感系统
- 提出一种生物启发 Biologically-Inspired 的触觉传感器
- 多模态 Multi-Modal 基于脉冲 Spiking-Based 的学习方法 VT-SNN
- 首次开源基于事件的视触数据集
0.2 Pro
- 结合事件传感器,快速感知
- 智能节能机器人 Intelligent Power-Efficient Robot Systems
1 Introduction
1.1 Background
- E.g. 从冰箱里拿一盒豆浆 (1)
- 人类通过 视觉–触觉 来操作,但是人脑比起 DNN 节能 [2], [3]
- 生物系统:异步,事件驱动 Asynchronous & Event-Driven
- 事件驱动的感知:节能且低延迟 Power-Efficiency & Low-Latency [Intel Loihi 芯片],对实时机器人系统友好
- 事件驱动的系统研究尚在研究
1.2 Algorithm
- 训练 VT-SNN 是基于脉冲反向传播 Spike-Based Backpropagation 的
- 促进早期分类:权重脉冲计数损失 Weighted Spike-Count Loss
1.3 Experiment
- 任务:物品分类和(旋转)滑动检测 Object Classification & (Rotational) Slip Detection
- 滑动检测:在 0.08 s 内正确检测到
- 视觉触觉的脉冲处理时间:1 ms
- 优势:比类似架构的 ANN 效果好,在 Intel Loihi 芯片上能够取得与GPU类似的性能,但能耗低一个数量级
2 Background & Related Work
2.1 Visual-Tactile Perception for Robots
- 最早追溯到1984年,描述物体表面
- 早期工作由于触觉传感器的分辨率低,触觉只是起到辅助支持作用
- 任务:object exploration[18], classification[19]-[21], shape completion[22], slip detection[23], [24]…
- 触觉传感器:BioTac (RGB), GelSight (optical-based)
- 生成视觉触觉数据的神经表示,用于强化学习[12]
2.2 Event-based Perception: Sensors and Learning
- 事件相机:the DVS and Prophesee Onboard… 异步捕获像素变化
- 事件触觉传感器:少,一般是事件相机 + 弹性材料
- Neuromorphic learning: SNN…
- Spiking Neural Network (SNN)
- Low latency
- High temporal resolution
- Low power consumption
- 但缺乏好的训练方式
- Spike 不可微,所以基于梯度反向传播算法的训练不行
- SLAYER: (approximate) back-propagation method for SNN
- 任务:emotion detection…
3 NeuTouch: An Event-Based Tactile Sensor
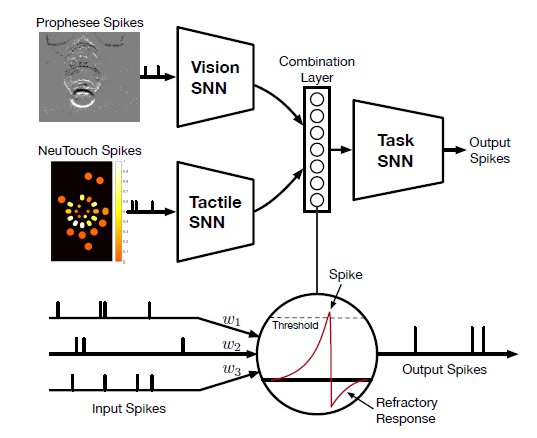
4 Visual-Tactile Spiking Neural Network (VT-SNN)
4.1 Model Architecture
4.1.1 Vision SNN
- Input: 100 x [2, 250, 200, 150]
- Architecture
- Polling Layer: kernel size = stride size = 4
- Fully Connection Layer: 2 dense spiking layers (spiking convolutional layers poor performance)
- Output: 10
| Input Dataset | Trials Number | Prophesee Resolution | Cropped Resolution | Time Steps |
|---|---|---|---|---|
| vis_xx.npy | 100 | 640 x 480 × 2 | 200 × 250 | 150 |
4.1.2 Tactile SNN
- Input: 100 x [78, 2, 150]
- Architecture:
- Polling Layer: kernel size = stride size = 4
- Fully Connection Layer: 2 dense spiking layers (spiking convolutional layers poor performance)
- Output: 50
| Input Dataset | Trials Number | NeuTouch Resolution | Processed Resolution | Time Steps |
|---|---|---|---|---|
| tact_xx.npy | 100 | 39 × 2 × 2 | No | 150 |
4.1.3 Task SNN
- Input: 60 = 10 (Visual) + 50 (Tactile)
- Architecture
- Agnostic to the size of the input time dimension 模型结构与输入的时间维度无关
- Output:
- 20: Container & Weight Classification
- 2: Rotational Slip Classification
4.2 Neuron Model
4.2.1 Spike Response Model (SRM)
- Incoming spikes $s_i(t)$ are convolved with a response kernel $\epsilon(\cdot)$ to yield a spike response signal that is scaled by a synaptic weight $w_i$
$$
u(t)=\sum w_i\left(\epsilon * s_i\right)(t)+(\nu * o)(t)
$$ - $u(t)$: internal state (membrane potential)
- $\varphi$: predefined threshold
- $w_i$: synaptic weight
- $*$: indicates convolution
- $s_i(t)$: incoming spikes from input $i$
- $\epsilon(\cdot)$: response kernel
- $\nu(\cdot)$: refractory kernel
- $o(t)$: neuron’s output spike train
4.3 Model Training
4.3.1 SLAYER:
- using a stochastic spiking neuron approximation to derive an approximate gradient
- a temporal credit assignment policy to distribute errors
4.3.2 Training Consideration
- Spiking data needs to be binned into fixed-width interval during the training process (on GPU)
- Used a straight-forward binning process
4.3.3 Details of Training
- (binary) value for each bin window $V_w$ was 1 whenever the total spike count in that window exceeded a threshold value $S_{min}$
$$
V_w= \begin{cases}1 & \sum_w S \geq S_{\min } \ 0 & \text { otherwise }\end{cases}
$$ - Class prediction is determined by the number of spikes in the output layer spike train
- Neuron that generates the most spikes represents the winning class
- Spike-Count loss Definition
- Captures the difference between the observed output spike count and the desired spike count across the output neurons (indexed by n)
$$
\mathcal{L}=\frac{1}{2} \sum_{n=0}^{N_o}\left(\sum_{t=0}^T \mathbf{s}^n(t)-\sum_{t=0}^T \tilde{\mathbf{s}}^n(t)\right)^2
$$
- Captures the difference between the observed output spike count and the desired spike count across the output neurons (indexed by n)
- A generalization of the spike-count loss above to incorporate temporal weighting
- Set $\omega(t)$ to be monotonically decreasing, which encourages early classification by down-weighting later spikes
- Used a simple quadratic function (其他的形式也应该可以)
$$
\omega(t)={\beta}t^2+\gamma \quad\text{with}\quad\beta<0
$$ - Appropriate counts have to be specified for the correct and incorrect classes and are task-specific hyperparameters.
- Tuned them manually and found that setting the positive class count to $≈$ 50% of the maximum number of spikes (across each input within the considered time interval) worked well
$
\mathcal{L}\omega=\frac{1}{2}\sum{n=0}^{N_o}\left(\sum_{t=0}^T\omega(t)\mathbf{s}^n(t)-\sum_{t=0}^T\omega(t)\tilde{\mathbf{s}}^n(t)\right)^2
$
$$
\mathcal{L}\omega=\frac{1}{2}\sum{n=0}^{N_o}\left(\sum_{t=0}^T\omega(t)\mathbf{s}^n(t)-\sum_{t=0}^T\omega(t)\tilde{\mathbf{s}}^n(t)\right)^2
$$
5 Robot & Sensor Setup
5.1 NeuTouch Tactile Sensor
5.2 Prophesee Event Camera
5.3 RGB Cameras
5.4 OptiTrack
6 Container & Weight Classification
7 Rotational Slip Classification
8 Discussion: Speed & Power Efficiency
9 Conclusion

最近发布